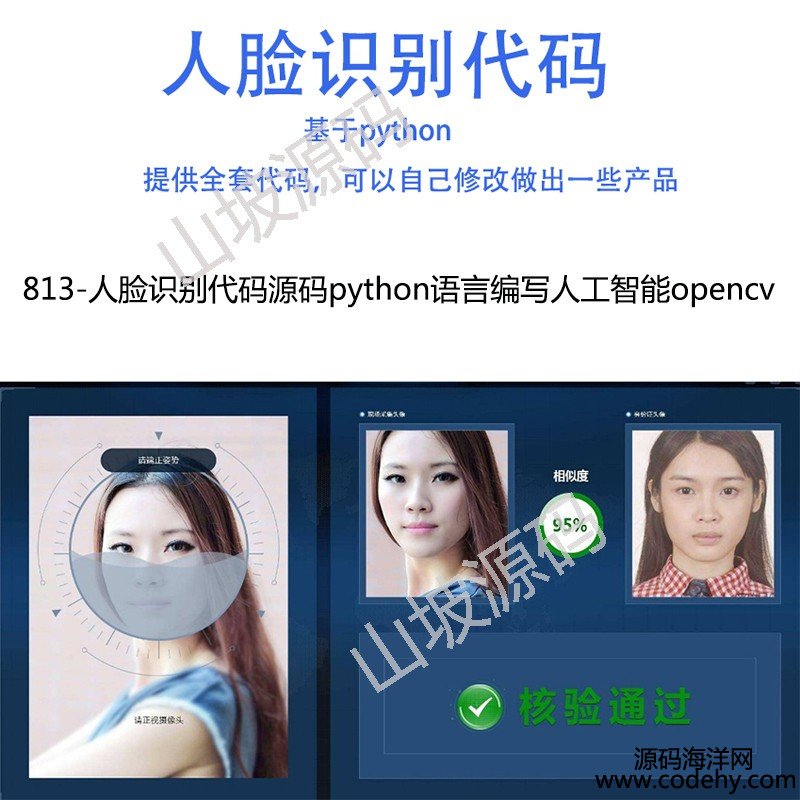
�e���aԴ�apython�Z�Ծ����˹�����opencv")
813-��Ę�R(sh��)�e���aԴ�apython�Z�Ծ����˹�����opencv
����(d��ng)�\(y��n)�У�python ��ֱ���\(y��n)�м��ɣ�
���ԣ���Դ�aֻ��10Ԫ�����ṩ���g(sh��)֧�֣��I��ȥ�����Լ��о��W(xu��)��(x��)�����ij��Լ�Ҫ�Įa(ch��n)Ʒ�����íh(hu��n)��֮Ć��}�Լ��W(w��ng)����һ�£�ʹ�ô�Դ�a��Ҫ��һ�c(di��n)python��opencv���A(ch��)������Ҳ��Ԕ��(x��)�f���ęn��
ʹ��py2.7�����\(y��n)�У����ʹ�ø��߰汾��3.5������Ҫ�Լ���������
�ھ���Ę�R(sh��)�e
1. �R(sh��)�e��Ę�ĿɔU(ku��)չ�ԡ�ԭ�е�demoֻ���R(sh��)�eһ��(g��)�ˣ��µ�demo�ڔ�(sh��)��(j��)���ĔU(ku��)չ�������ģ���Փ�Ͽ����R(sh��)�e�o��(sh��)�˵�Ę��ֻҪ��������Ĕ�(sh��)��(j��)��
2.��(j��ng)�W(w��ng)�j(lu��)�O(sh��)Ӌ(j��)���Ӻ�(ji��n)�Ρ��µ�demo�ھ��e��(j��ng)�W(w��ng)�j(lu��)���O(sh��)Ӌ(j��)�ϱ�ԭ�еľ��e��(j��ng)�W(w��ng)�j(lu��)���Ӻ�(ji��n)�κ��������⣬�]�и����ô��(f��)�s�������m�����T��3. ���a�Y(ji��)��(g��u)�������������O(sh��)Ӌ(j��)����ģ�K�������ܲ�ֳ����ıM����ֳ�����������ÿ��(g��)�ļ������ԆΪ�(d��)�ó���y(c��)ԇ��ʹ�ã�
4Ԕ�M������עጡ�����Կ���Ԕ��(x��)��Ԕ��(x��)������עጡ����ÿ����ĺ�Ӣ�ĵ�ע���......
Step 1 �h(hu��n)������ �h(hu��n)�������@�K���W(w��ng)�ϵ��Y�Ϸdz��࣬���w���f�ҽo��ҵĽ��h�ǣ�ʹ�ü���python�h(hu��n)��Anaconda�������ѽ�(j��ng)�����˺ܶ����õİ��b�������fnumpy��scipy����ȥ���Լ����õ�ʹ�ࣻͨ�^Anaconda���b�µ�Ӌ(j��)���Ҳ�dz����㣬���w�Ͳ���٘���ˣ��W(w��ng)�Ͽ����ҵ��ܶ�̳̣���ٶȡ���Google���ҿ���������һ����ǣ�����Anaconda��theano߀��tensorflow�İ������c(di��n)С���}����Ҫ?ji��ng)h��Ȼ���������d���ã��W(w��ng)��Ҳ�н̡̳�
��(ji��n)����֮��ʹ��Anaconda�����b�ñ�Ҫ�ĿƌW(xu��)Ӌ(j��)�����numpy,scipy,sklearn,keras,opencv���Nһ��(g��)�e�˵ĭh(hu��n)�����ý̳�,�H��������
http://machinelearningmastery.com/setup-python-environment-machine-learning-deep-learning-anaconda/
Step 2 �@��Ӗ(x��n)����(sh��)��(j��)�� �ڶ�������Ҫ�@�Ô�(sh��)��(j��)Ӗ(x��n)����������ԏľW(w��ng)����Ӗ(x��n)������Ҳ�������Լ��������ѵ���Ƭ�����زģ���־���(x��)��opencv��os�������w�����k�����ęn�С�


�j(lu��)�(y��n)�C4.0�̘I(y��)��Դ�a ���Z�ԾW(w��ng)�j(lu��)�(y��n)�C���M(f��i)ϵ�y(t��ng) ��ҕ�l�̳�0")
վԴ�a��Q+web��360��ȫ���桢115��(y��ng)����������1")